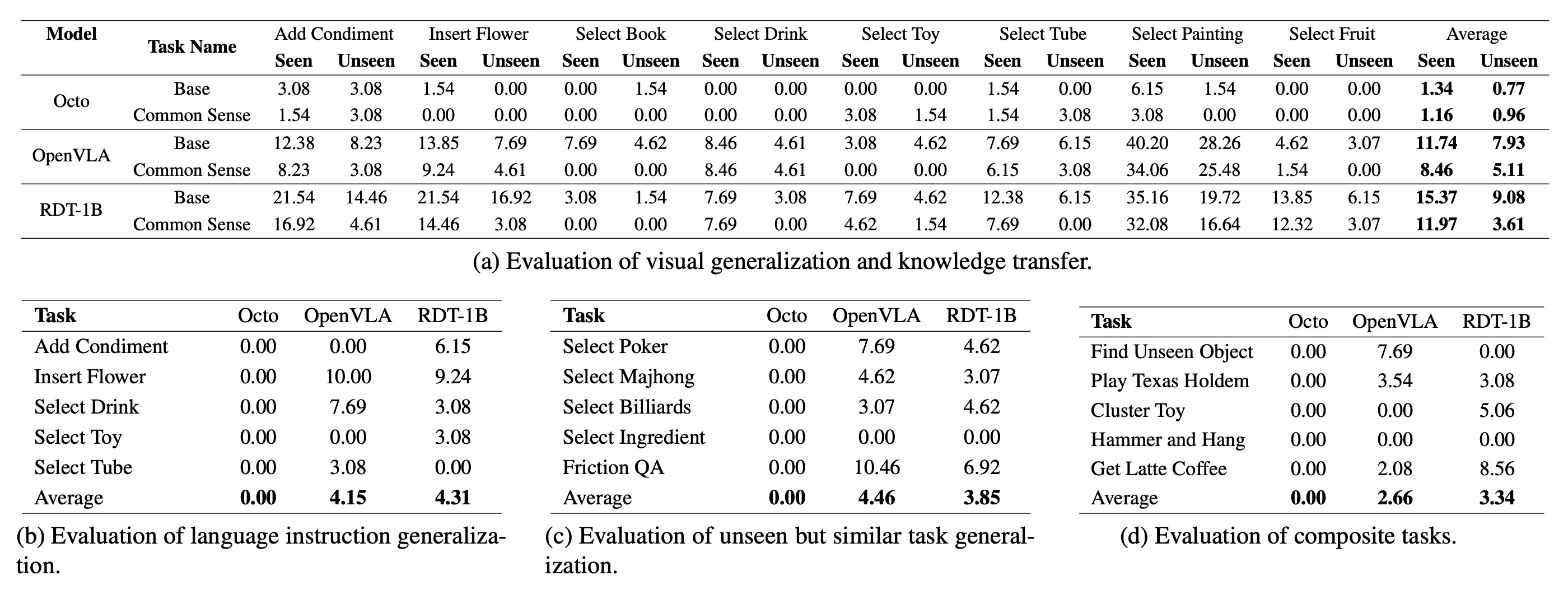
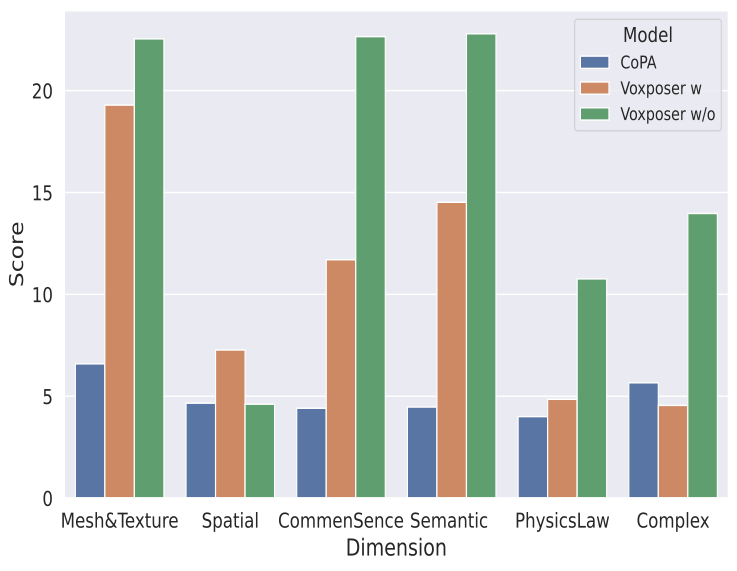
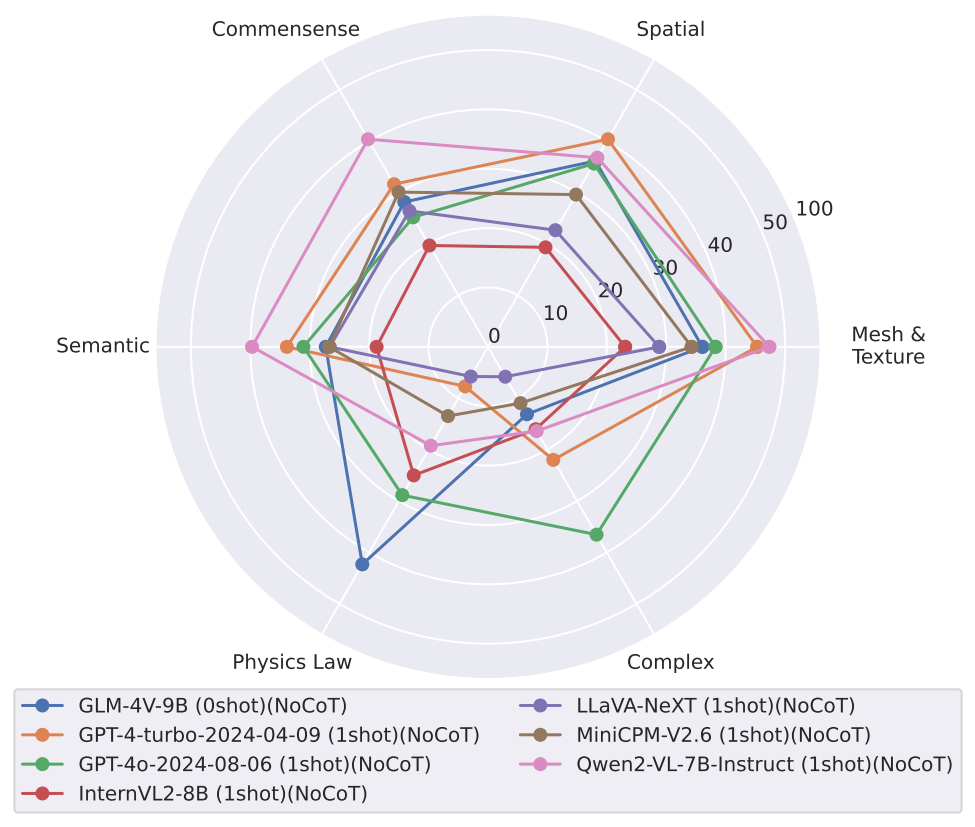
From the perspective of “intelligence”, it is divided into six capability dimensions:
- Mesh & Texture Understanding. It should be able to recognize irregular and uniquely shaped meshes as well as diversified textures with rich semantic information. This involves basic open-vocabulary object recognition, OCR capabilities and etc.
- Spatial Understanding. It should possess basic spatial perception abilities, enabling accurate judgment of the relative positions of objects in an image,spatial constraints between different objects, and even direct distance estimation.
- Common Sense & World Knowledge Transfer. It should acquire world knowledge and common sense from large-scale pretraining and apply such priors to corresponding tasks. For example, associating visual information with world knowledge to align it with user requirements.
- Semantic Instruction Understanding. It should retain strong language comprehension abilities, enabling it to extract user needs from natural interactions or understand the implicit goals of a task, and then execute dynamic action sequences. Instead of template instructions like “pick A and then place it to B”.
- Physical Laws Understanding. It should understand the principles of the physical world, such as friction, gravity, acceleration, and even fundamental physical concepts like the lever principle.
- Long-Horizon Reasoning. Reasoning here primarily refers to the ability to plan for long-horizon, multi-step tasks, where logical correlations between multiple action steps are required. Broader reasoning encompasses several of the aforementioned abilities, such as semantic inference, the incorporation of world knowledge, and alignment between vision and task objectives. However, in this context, we focus solely on the former.